Set theory applied on sorted and deduplicated slices. Much performance! Such Wow!
API Documentation can be found on docs.rs.
sdset stands for sorted-deduplicated-slices-set which is a little bit too long.
Note about the tests, which are done on ranges of integer, if it ends with:
-
two_slices_big, the first slice contains0..100and the second has1..101 -
two_slices_big2, the first contains0..100and the second has51..151 -
two_slices_big3, the first contains0..100and the second has100..200 -
three_slices_big, the first contains0..100, the second has1..101and the third has2..102 -
three_slices_big2, the first contains0..100, the second has34..134and the third has67..167 -
three_slices_big3, the first contains0..100, the second has100..200and the third has200..300
These slices of runs of integer are useful when they overlap, we can see how performances changes when different parts of the slices overlaps.
For more informations on "Why is there no really big slices benchmarks ?", you can see my response on /r/rust.
To run the benchmarks you must enable the unstable feature.
$ cargo bench --features unstableNote that the sdset set operations does not need many allocations so it starts with a serious advantage. For more information you can see the benchmarks variance.
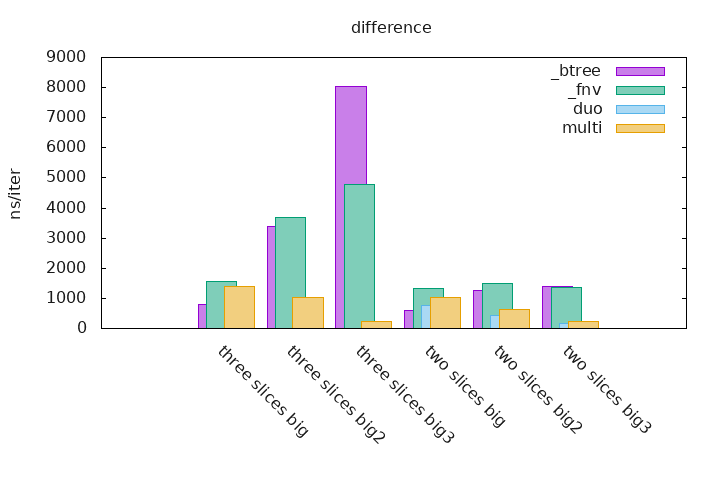
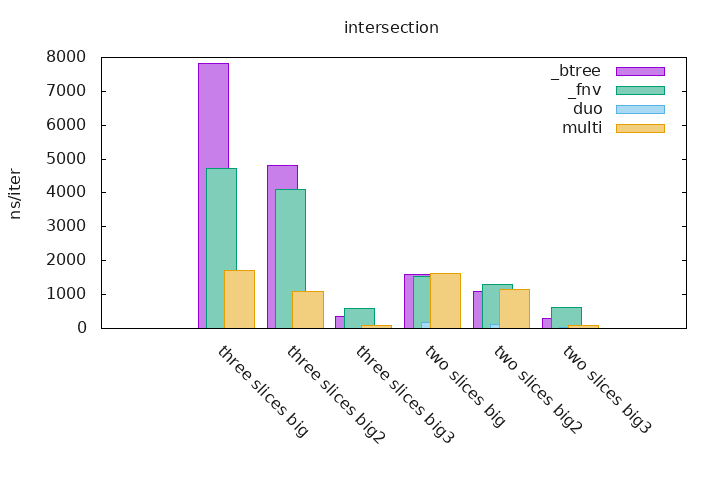
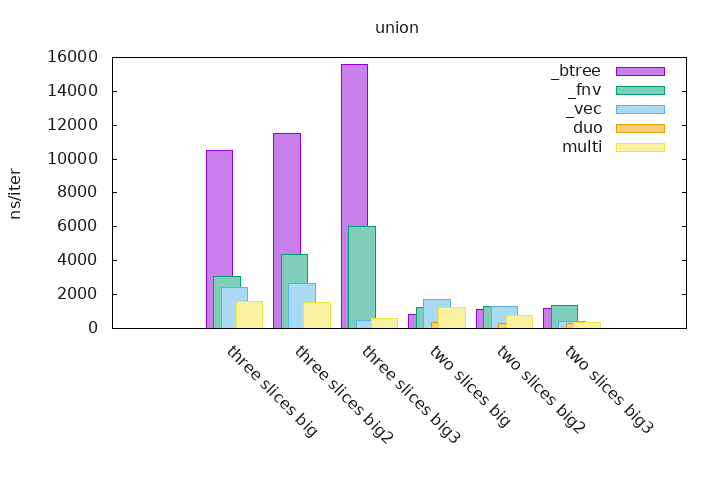
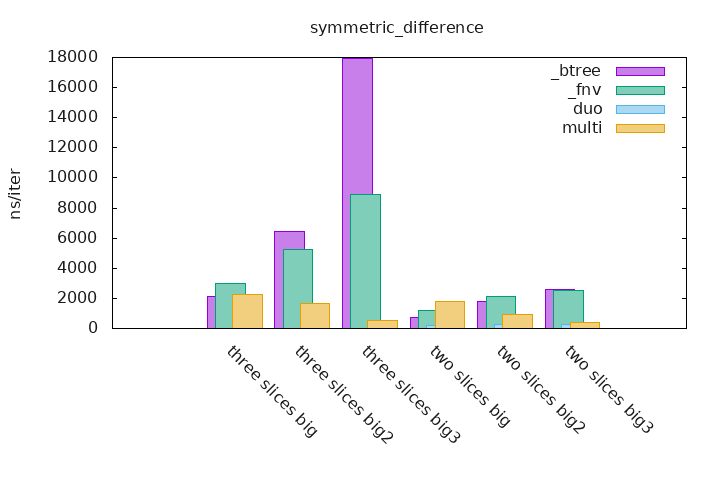
_btree are benchmarks that uses two or three BTreeSets which contains runs of integers (see above), the BTreeSets creations are not taken into account. The set operations are done on these sets and the result is accumulated in a final Vec.
_fnv are benchmarks that uses two or three HashSets which contains runs of integers (see above), it uses a custom Hasher named fnv that is specialized for little values like integers, the HashSets creations are not taken into account. The set operations are done on these sets and the result is accumulated in a final Vec.
The _vec benchmarks are available for the union set operation only, it consist of a Vec which is populated with the elements of two or three slices (see above), sorted and deduplicated.
The duo and multi measurements are the implementations that are part of this crate, the first one can only do set operations on two sets and the second one can be used for any given number of sets.
Histograms can be generated using the benchmarks by executing the following command:
$ export CARGO_BENCH_CMD='cargo bench --features unstable'
$ ./gen_graphs.sh xxx.benchThis is much more easier to read statistics and to see how sdset is more performant on already sorted and deduplicated slices than any other kind of collection.