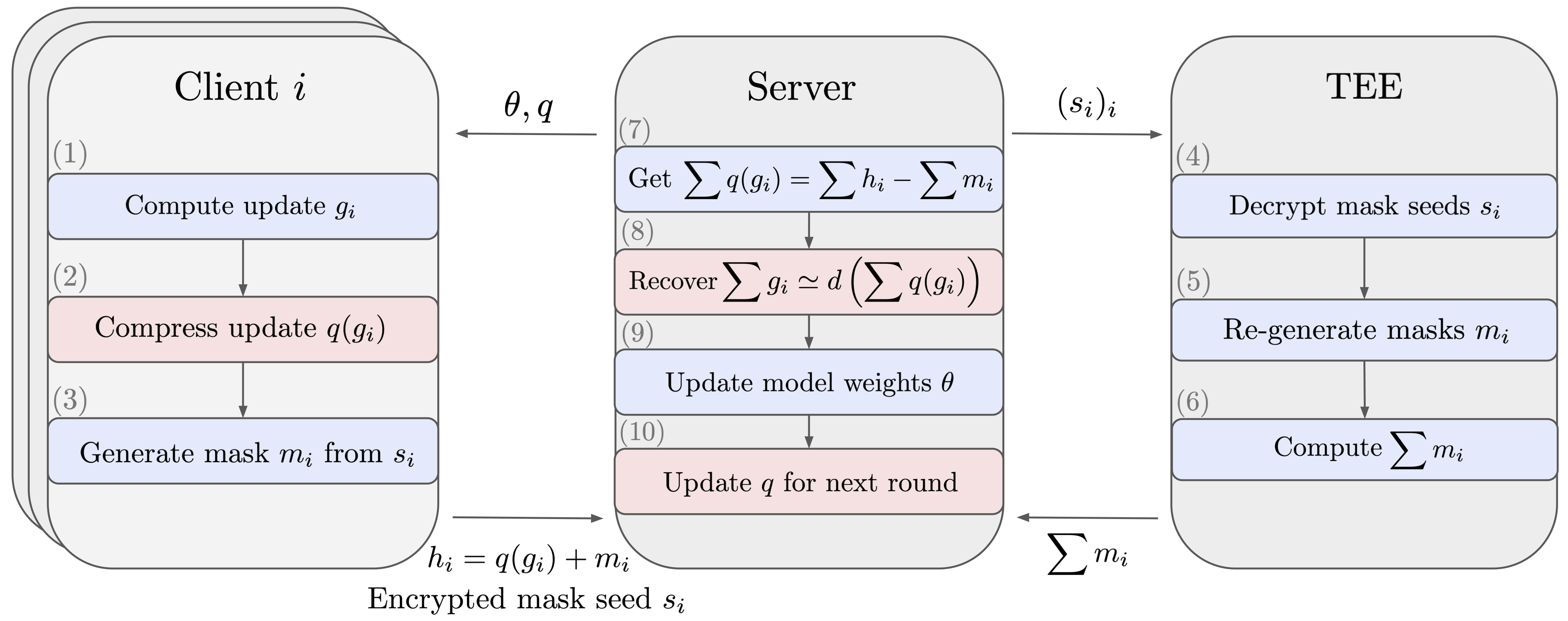
This repository contains the code to reproduce the results of the paper Reconciling Security and Communication Efficiency in Federated Learning. We implement various compression methods (scalar quantization, random pruning, product quantization) for compressing (uplink) model updates sent from the clients to the server in FLSim. The implementation modifies the underling compression methods to be compatible with the Secure Aggregation protocol, which ensures that the server only sees the aggregated model updates across all clients participating in the current round. The results presented in the code were run on FLSim version 0.1.0
The dependencies can be installed with: pip install -r requirements.txt.
To reproduce our results, on say the CelebA dataset, run cd examples/, follow the instructions in celeba_example.py to download the dataset and partition it by users and finally run:
python celeba_example.py --config-file configs/target_config_file.json
where target_config_file.json can be set to:
-
celeba_config.jsonfor uncompressed baseline -
celeba_sq_config.jsonfor scalar quantization with Secure Aggregation -
celeba_pruning_config.jsonfor Random Pruning with Secure Aggregation -
celeba_pq_config.jsonfor PQ with SecureIndexing
Feel free to vary the arguments of the "channel" field to test all the possible compression ratios!
This code is released under Apache 2.0, as found in the LICENSE file.
Please consider citing [1] if you found the resources in this repository and/or the paper useful.
[1] Prasad, Karthik and Ghosh, Sayan and Cormode, Graham and Mironov, Ilya and Yousefpour, Ashkan and Stock, Pierre. Reconciling Security and Communication Efficiency in Federated Learning.
@misc{prasad2022reconciling,
title = {Reconciling Security and Communication Efficiency in Federated Learning},
author = {Prasad, Karthik and Ghosh, Sayan and Cormode, Graham and Mironov, Ilya and Yousefpour, Ashkan and Stock, Pierre},
year = {2022}
}