


![]()
Machine Learning models should play by the rules, literally.
Back in the old days, it was common to write rule-based systems. Systems that do;

Nowadays, it's much more fashionable to use machine learning instead. Something like;

We started wondering if we might have lost something in this transition. Sure, machine learning covers a lot of ground but it is also capable of making bad decisions. We need to remain careful about hype. We also shouldn't forget that many classification problems can be handled by natural intelligence too. If nothing else, it'd sure be a sensible benchmark.
This package contains scikit-learn compatible tools that should make it easier to construct and benchmark rule based systems that are designed by humans. You can also use it in combination with ML models.
You can install this tool via pip.
python -m pip install human-learnThe project builds on top of a modern installation of scikit-learn and pandas. It also uses bokeh for interactive jupyter elements, shapely for the point-in-poly algorithms and clumper to deal with json datastructures.
Detailed documentation of this tool can be found here.
A free video course can be found on calmcode.io.
This library hosts a couple of models that you can play with.
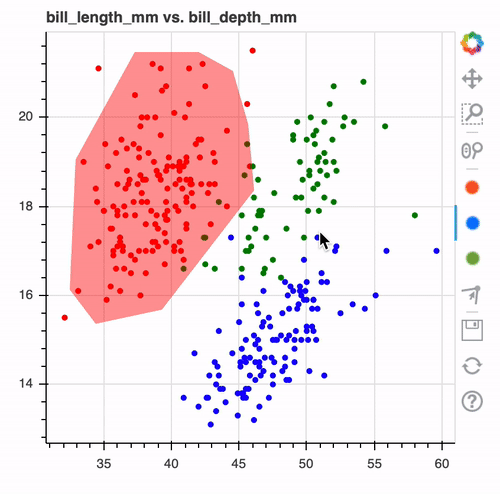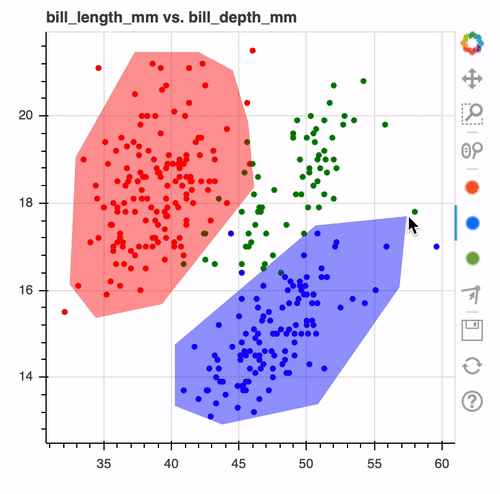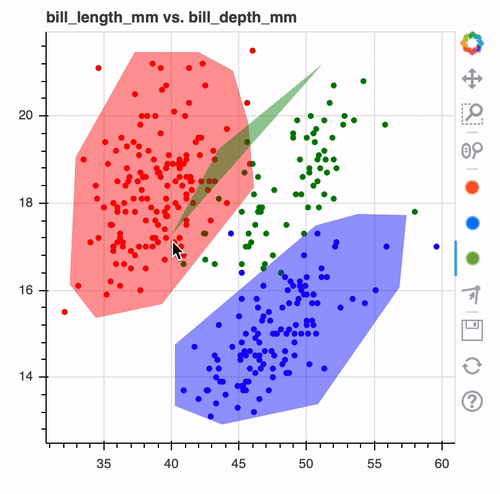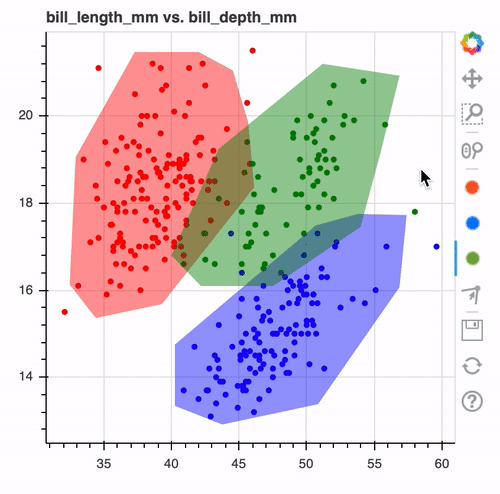
This tool allows you to draw over your datasets. These drawings can later be converted to models or to preprocessing tools.
This allows you to define a function that can make classification predictions. It's constructed in such a way that you can use the arguments of the function as a parameter that you can benchmark in a grid-search.
This allows you to draw decision boundaries in interactive charts to create a model. You can create charts interactively in the notebook and export it as a scikit-learn compatible model.
This allows you to define a function that can make regression predictions. It's constructed in such a way that you can use the arguments of the function as a parameter that you can benchmark in a grid-search.
This allows you to define a function that can declare outliers. It's constructed in such a way that you can use the arguments of the function as a parameter that you can benchmark in a grid-search.
This allows you to draw decision boundaries in interactive charts to create a model. If a point falls outside of these boundaries we might be able to declare it an outlier. There's a threshold parameter for how strict you might want to be.
This allows you to define a function that can handle preprocessing. It's
constructed in such a way that you can use the arguments of the function as a parameter
that you can benchmark in a grid-search. This is especially powerful in combination
with the pandas .pipe method. If you're unfamiliar with this amazing feature, you
may appreciate this tutorial.
This allows you to draw features that you'd like to add to your dataset or
your machine learning pipeline. You can use it via tfm.fit(df).transform(df) and
df.pipe(tfm).
This library hosts the popular titanic survivor dataset for demo purposes. The goal of this dataset is to predict who might have survived the titanic disaster.
The fish market dataset is also hosted in this library. The goal of this dataset is to predict the weight of fish. However, it can also be turned into a classification problem by predicting the species.
We're open to ideas for the repository but please discuss any feature you'd like to add before working on a PR. This way folks will know somebody is working on a feature and the implementation can be discussed with the maintainer upfront.
If you want to quickly get started locally you can run the following command to set the local development environment up.
make develop
If you want to run all the tests/checks locally you can run.
make check
This will run flake8, black, pytest and test the documentation pages.