This is a from-scratch implementation of deep quality networks (DQN) inspired by OpenAI's paper Hindsight Experience Replay. In this task, an agent must perform bit flipping actions to transform a given binary string to a given target string with only sparse rewards.
This repo replicates the results found in the paper and allows for experimentation with virtual goal parameters for better performance.
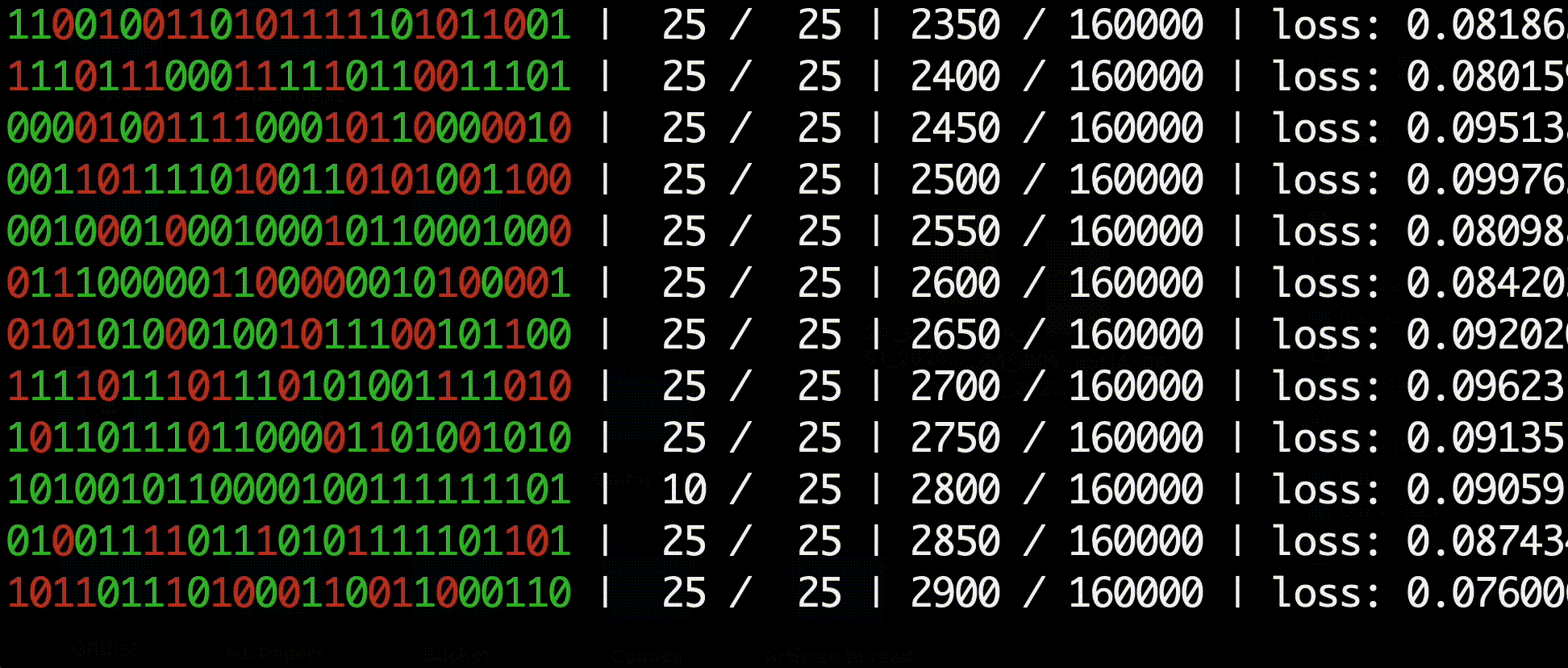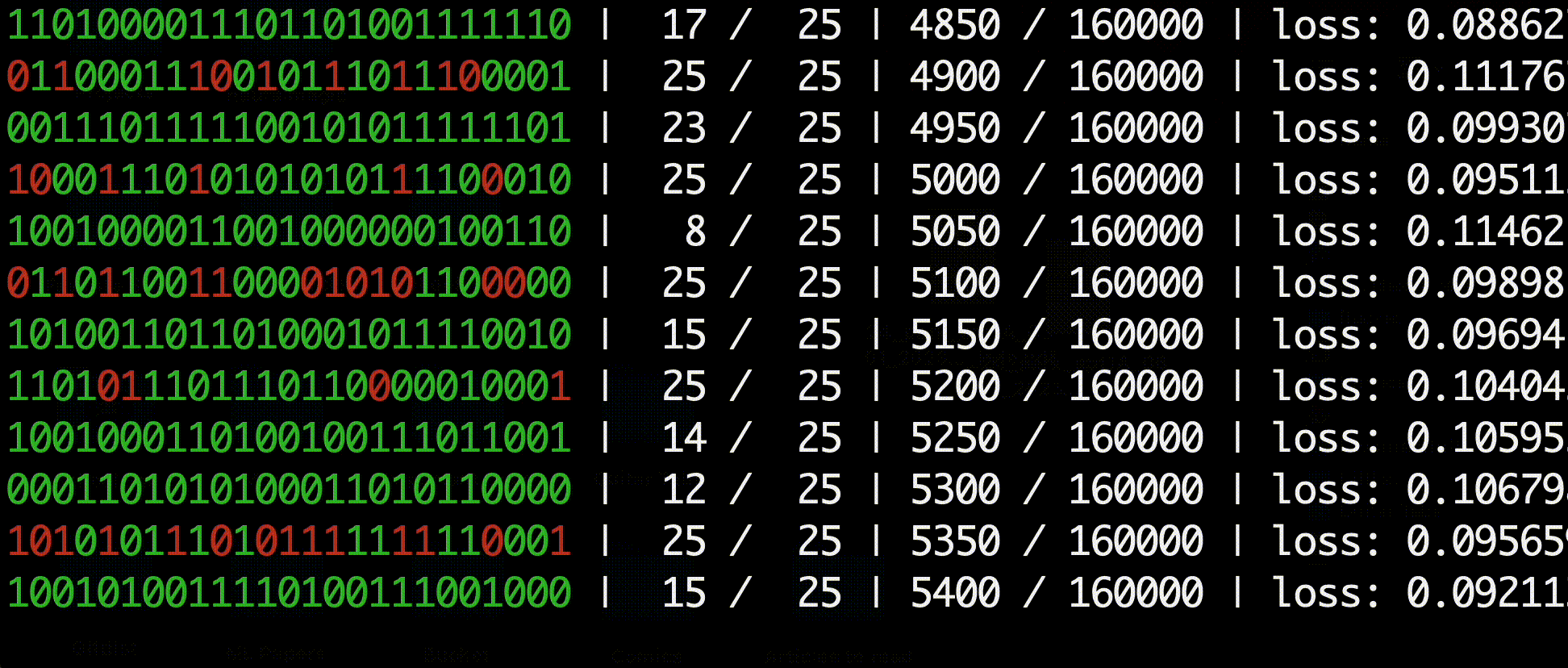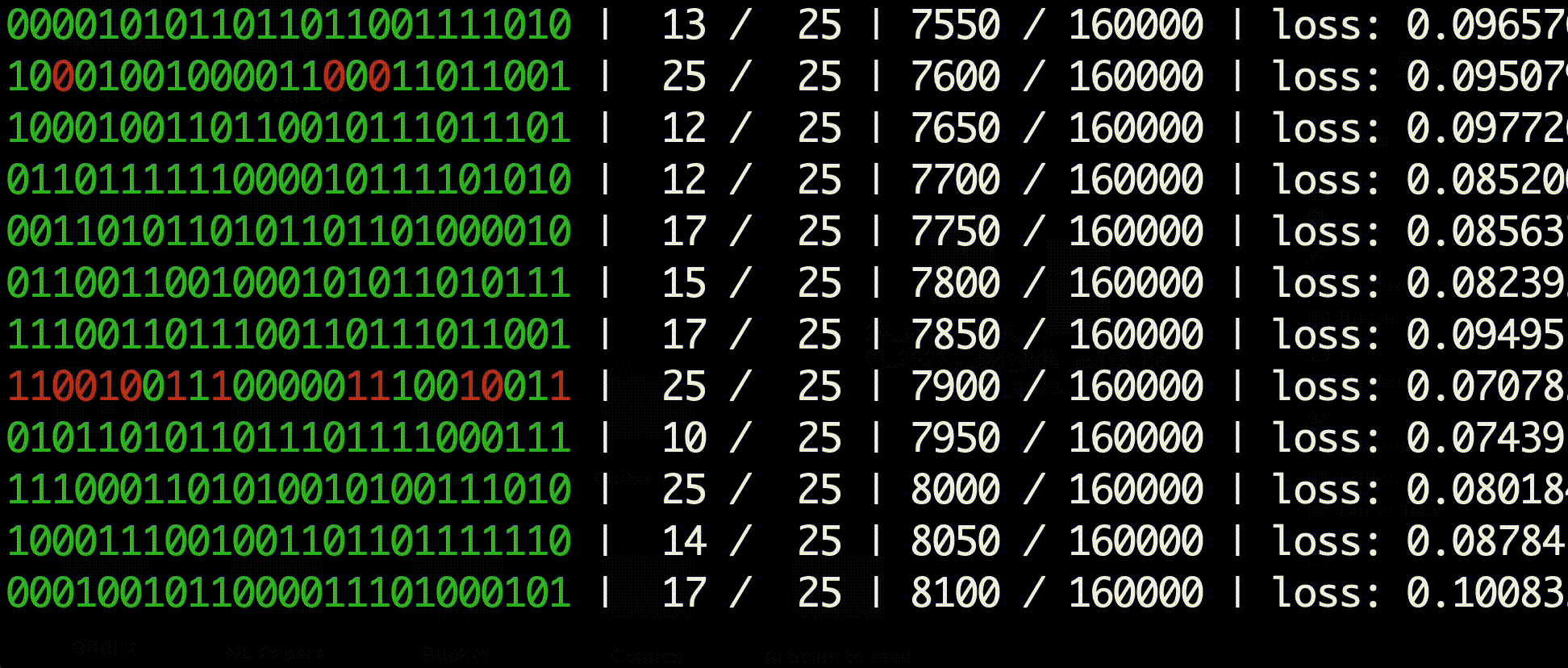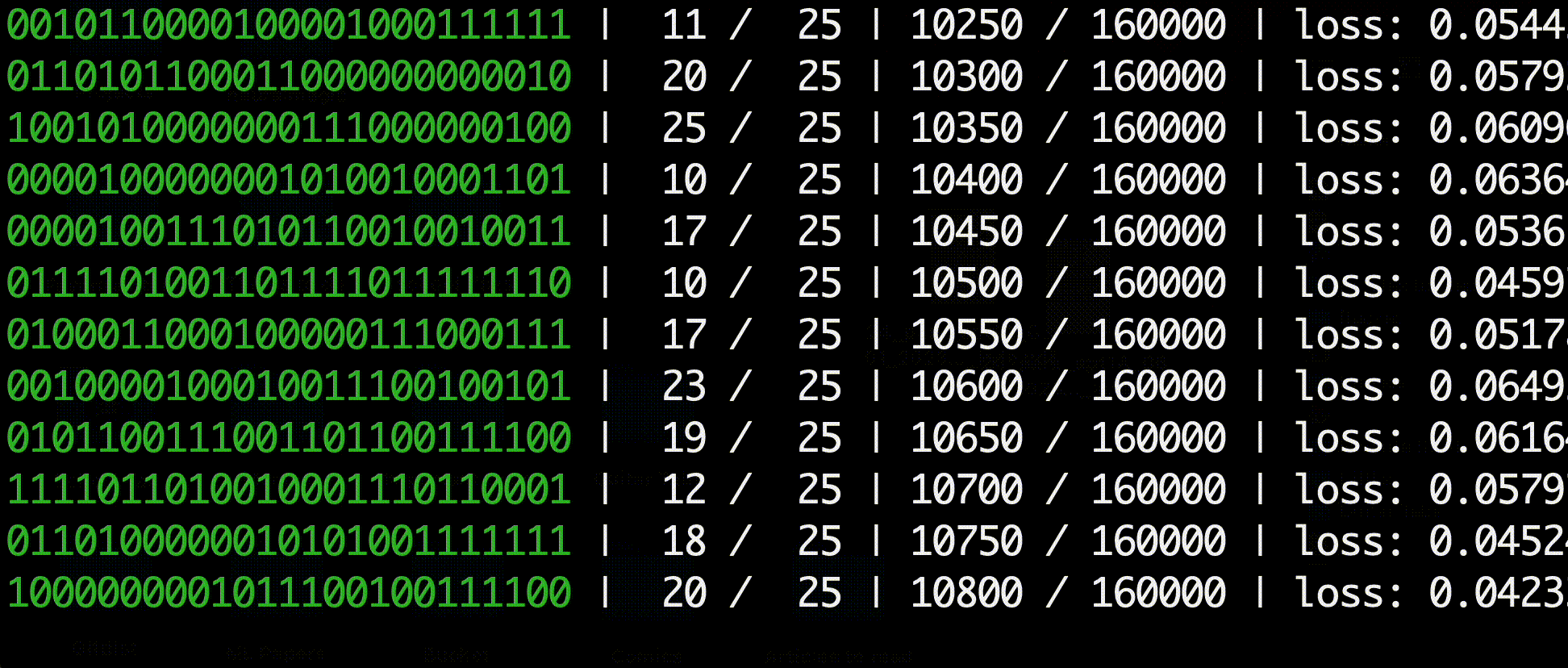
The environment consists of a binary string of 1s and 0s with another binary goal string that the agent must transform the initial string into. For example, the optimal actions for a string of length 3 would look like this:
GOAL: [0 1 1]
STRING: [1 0 1] -> [0 0 1] -> [0 1 1]
With some domain knowledge, an implementer could create a shaped reward function that rewards an agent for taking actions that move the string closer to its goal (such as a norm function). However, for many high level tasks, the implementer does know ahead of time the precise reward function capable of smoothly guiding for an agent to the goal. In HER OpenAI researchers consider the case in which the rewards are extremely sparse: +1 reward if the strings match exactly, -1 reward otherwise.
A typical agent is not capable of solving strings longer than 15 bits since it is statistically improbable that the agent would randomly encounter the goal enough to learn from positive rewards. The agent would therefore only receive negative rewards and be incapable of learning how to reach the goal.
In the HER paper the authors propose a method of artificially injecting positive-reward experiences into the replay buffer. For each action, in addition to experience sample generated by the action, the authors modify the replay's goal string to be the replay's next state, resulting in a replay with a guaranteed postiive positive reward. These "virtual goals" allow the agent to learn from immediate positive rewards without relying on random sampling from the environment.
My results were able to replicate the authors' findings up to 30 bit strings. The authors did not include many details about hyperparameters in the paper, so it is possible that longer strings are solvable with different parameters such as a larger replay buffer and more training episodes.