Status: Archive (code is provided as-is, no updates expected)
Code for Learning to Generate Reviews and Discovering Sentiment (Alec Radford, Rafal Jozefowicz, Ilya Sutskever).
Right now the code supports using the language model as a feature extractor.
from encoder import Model
model = Model()
text = ['demo!']
text_features = model.transform(text)
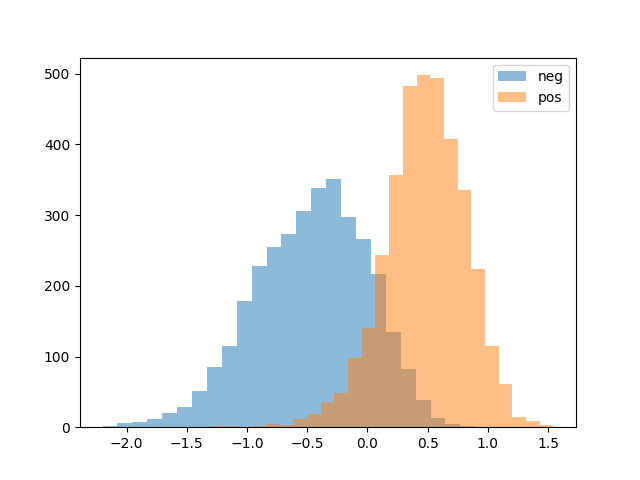
A demo of using the features for sentiment classification as reported in the paper for the binary version of the Stanford Sentiment Treebank (SST) is included as sst_binary_demo.py. Additionally this demo visualizes the distribution of the sentiment unit like Figure 3 in the paper.
Additionally there is a PyTorch port made by @guillitte which demonstrates how to train a model from scratch.
This repo also contains the parameters of the multiplicative LSTM model with 4,096 units we trained on the Amazon product review dataset introduced in McAuley et al. (2015) [1]. The dataset in de-duplicated form contains over 82 million product reviews from May 1996 to July 2014 amounting to over 38 billion training bytes. Training took one month across four NVIDIA Pascal GPUs, with our model processing 12,500 characters per second.
[1] McAuley, Julian, Pandey, Rahul, and Leskovec, Jure. Inferring networks of substitutable and complementary products. In Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, pp. 785–794. ACM, 2015.