The goal of this project is to try to simulate plasuible scanpaths, fixations and saccade, in free viewing condition.

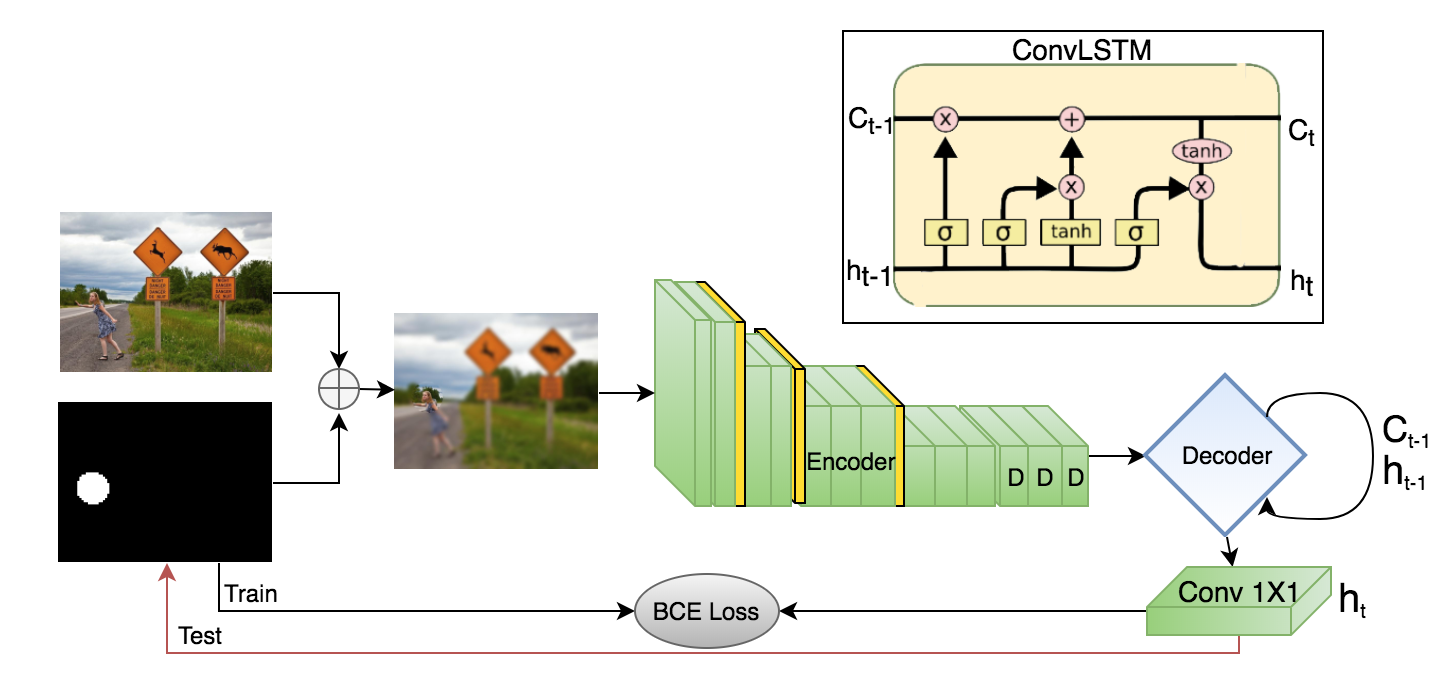
Two model has been implemented based on foveatin technique. First iteration is always with full reslution image and it will follow with foveated inputs based on previous fixation chosen by the model.
A is Based on learning quantizing saliency volumes with q=400ms.
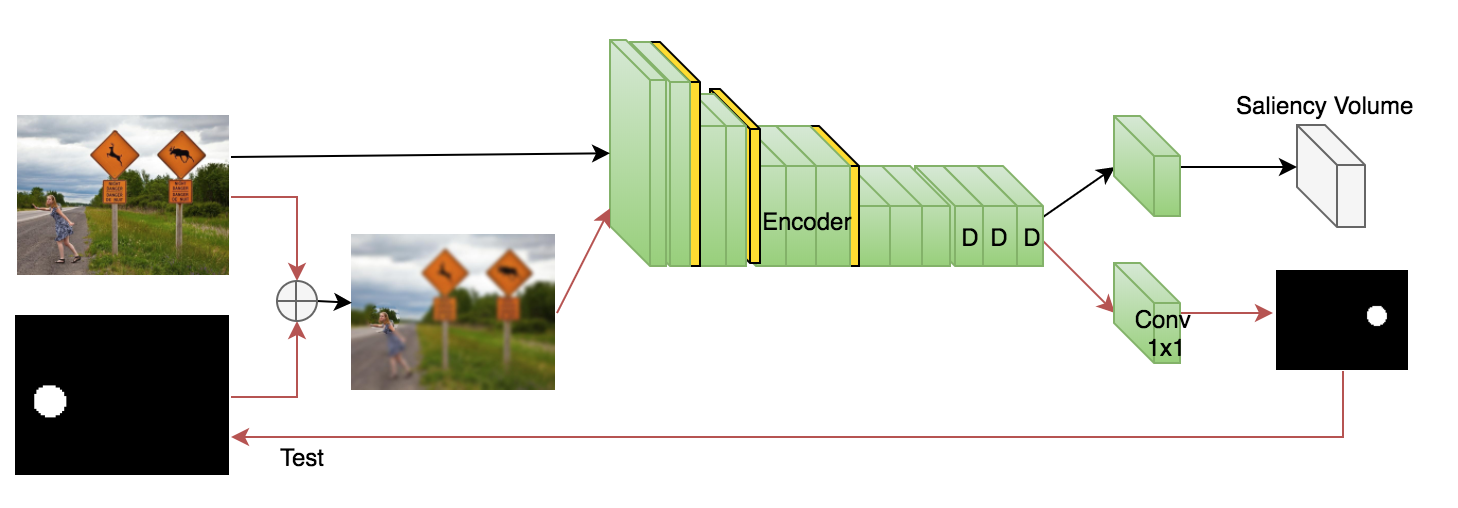
B is an Encoder-Decoder model based on use of normal and bidirectional ConvLSTMs as decoder.
Please make sure to checkout SEQUAL to find datasetes and metrics used in this project.