See our technical paper here: https://arxiv.org/abs/2205.09123
We can match PPO and A2C's performance exactly by doing the following tweaks in PPO:
- Match the learning rate parameter to be exactly $0.0007$ (also means turning off learning rate annealing), the entropy coefficient to $0$, and the number of steps to be $5$.
- Turn off advantage normalization
- Disable GAE by setting its
lambdaparameter to 1. - Set the number of update epochs $K$ to 1, so the clipped objective has nothing to clip.
- Perform update on the whole batch of training data (
batch_size = n_envs * n_steps) - Disable value function clipping.
- Use A2C's RMSprop optimizer and configurations

To see it in action, run
poetry install
poetry run python sb3_ppo.py
poetry run python sb3_a2c.pywe get the following screenshot, which shows the sum of the updated models' first layer's weights and they are exactly the same
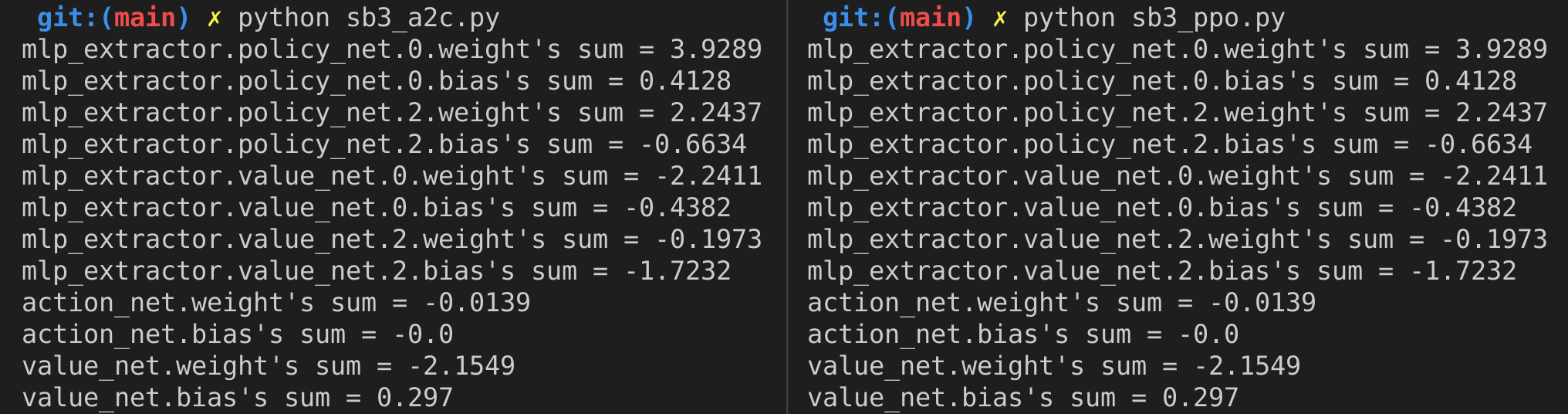
Therefore, A2C is a special case of PPO when PPO 1) uses learning rate $=0.0007$ and turn off learning rate annealing, 2) set entropy coefficient $=0$, 3) set number of steps $=5$, 4) turn off advantage normalization, 5) disable GAE, 6) set update epoch $K=1$, 7) use whole batch of data for update, 8) disable value function clipping, and 9) use the RMSprop optimizer.
@misc{https://doi.org/10.48550/arxiv.2205.09123,
doi = {10.48550/ARXIV.2205.09123},
url = {https://arxiv.org/abs/2205.09123},
author = {Huang, Shengyi and Kanervisto, Anssi and Raffin, Antonin and Wang, Weixun and Ontañón, Santiago and Dossa, Rousslan Fernand Julien},
keywords = {Machine Learning (cs.LG), FOS: Computer and information sciences, FOS: Computer and information sciences},
title = {A2C is a special case of PPO},
publisher = {arXiv},
year = {2022},
copyright = {arXiv.org perpetual, non-exclusive license}
}