This is an implementation of Value Iteration Networks (VIN) in TensorFlow to reproduce the results.(PyTorch version)
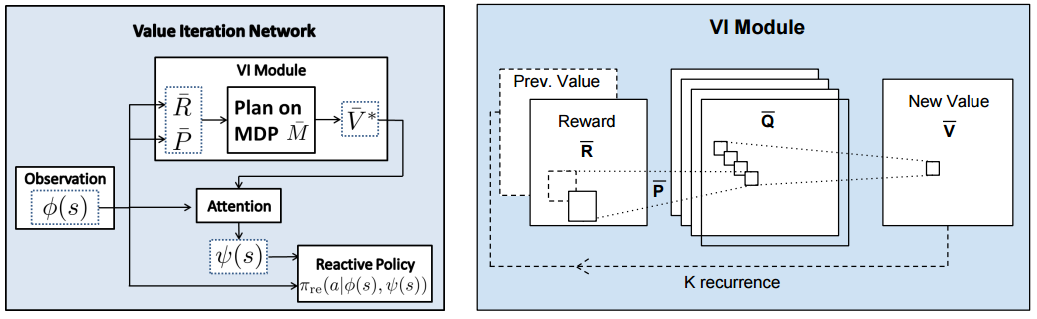
- A fully differentiable neural network with a 'planning' sub-module.
- Value Iteration = Conv Layer + Channel-wise Max Pooling
- Generalize better than reactive policies for new, unseen tasks.
| Visualization | Grid world | Reward Image | Value Images |
|---|---|---|---|
| 8x8 |  |
 |
 |
| 16x16 |  |
 |
 |
| 28x28 |  |
 |
 |
This repository requires following packages:
- Python >= 3.6
- Numpy >= 1.12.1
- TensorFlow >= 1.0
- SciPy >= 0.19.0
Each data sample consists of (x, y) coordinates of current state in grid world, followed by an obstacle image and a goal image.
| Dataset size | 8x8 | 16x16 | 28x28 |
|---|---|---|---|
| Train set | 77760 | 776440 | 4510695 |
| Test set | 12960 | 129440 | 751905 |
python run.py --datafile data/gridworld_8x8.npz --imsize 8 --lr 0.005 --epochs 30 --k 10 --batch_size 128python run.py --datafile data/gridworld_16x16.npz --imsize 16 --lr 0.008 --epochs 30 --k 20 --batch_size 128python run.py --datafile data/gridworld_28x28.npz --imsize 28 --lr 0.003 --epochs 30 --k 36 --batch_size 128Flags:
-
datafile: The path to the data files. -
imsize: The size of input images. From: [8, 16, 28] -
lr: Learning rate with RMSProp optimizer. Recommended: [0.01, 0.005, 0.002, 0.001] -
epochs: Number of epochs to train. Default: 30 -
k: Number of Value Iterations. Recommended: [10 for 8x8, 20 for 16x16, 36 for 28x28] -
ch_i: Number of channels in input layer. Default: 2, i.e. obstacles image and goal image. -
ch_h: Number of channels in first convolutional layer. Default: 150, described in paper. -
ch_q: Number of channels in q layer (~actions) in VI-module. Default: 10, described in paper. -
batch_size: Batch size. Default: 128
NOTE: This is the accuracy on test set. It is different from the table in the paper, which indicates the success rate from rollouts of the learned policy in the environment.
| Test Accuracy | 8x8 | 16x16 | 28x28 |
|---|---|---|---|
| TensorFlow | 99.03% | 90.2% | 82% |
| PyTorch | 99.16% | 92.44% | 88.20% |
| Speed per epoch | 8x8 | 16x16 | 28x28 |
|---|---|---|---|
| TensorFlow | 4s | 25s | 165s |
| PyTorch | 3s | 15s | 100s |
-
Q: How to get reward image from observation ?
- A: Observation image has 2 channels. First channel is obstacle image (0: free, 1: obstacle). Second channel is goal image (0: free, 10: goal). For example, in 8x8 grid world, the shape of an input tensor with batch size 128 is [128, 2, 8, 8]. Then it is fed into a convolutional layer with [3, 3] filter and 150 feature maps, followed by another convolutional layer with [3, 3] filter and 1 feature map. The shape of the output tensor is [128, 1, 8, 8]. This is the reward image.
-
Q: What is exactly transition model, and how to obtain value image by VI-module from reward image ?
- A: Let us assume batch size is 128 under 8x8 grid world. Once we obtain the reward image with shape [128, 1, 8, 8], we do convolutional layer for q layers in VI module. The [3, 3] filter represents the transition probabilities. There is a set of 10 filters, each for generating a feature map in q layers. Each feature map corresponds to an "action". Note that this is larger than real available actions which is only 8. Then we do a channel-wise Max Pooling to obtain the value image with shape [128, 1, 8, 8]. Finally we stack this value image with reward image for a new VI iteration.